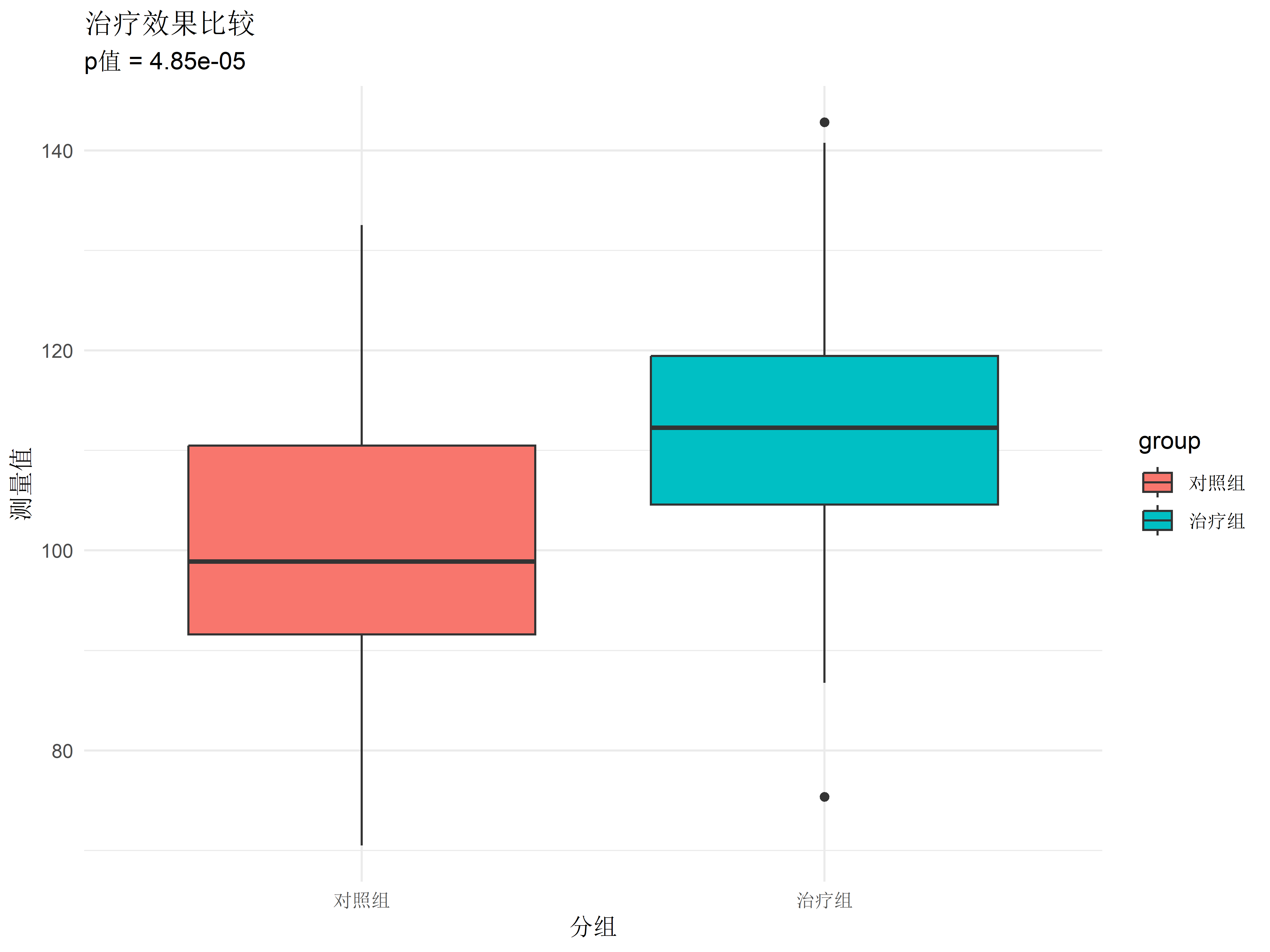
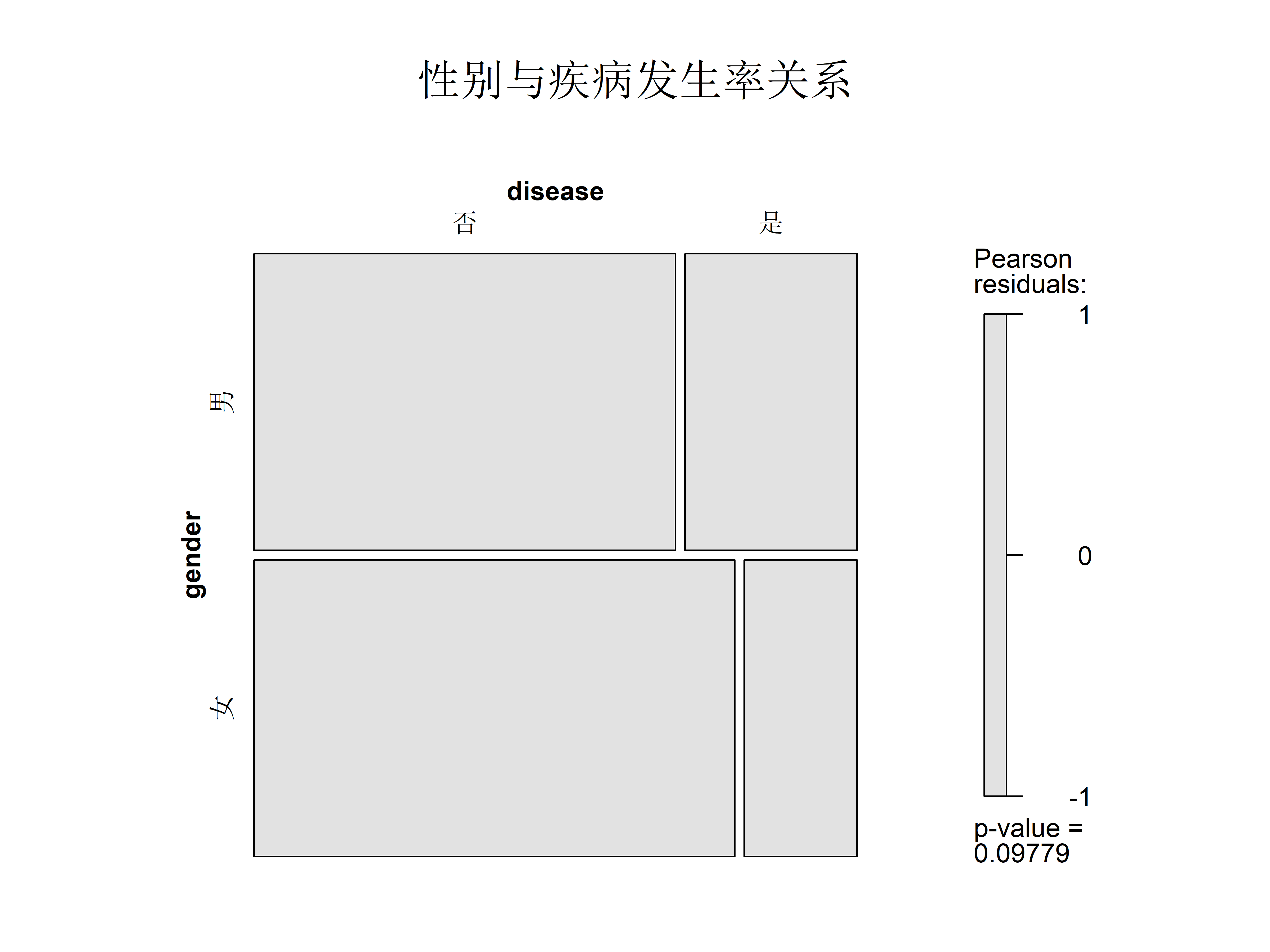
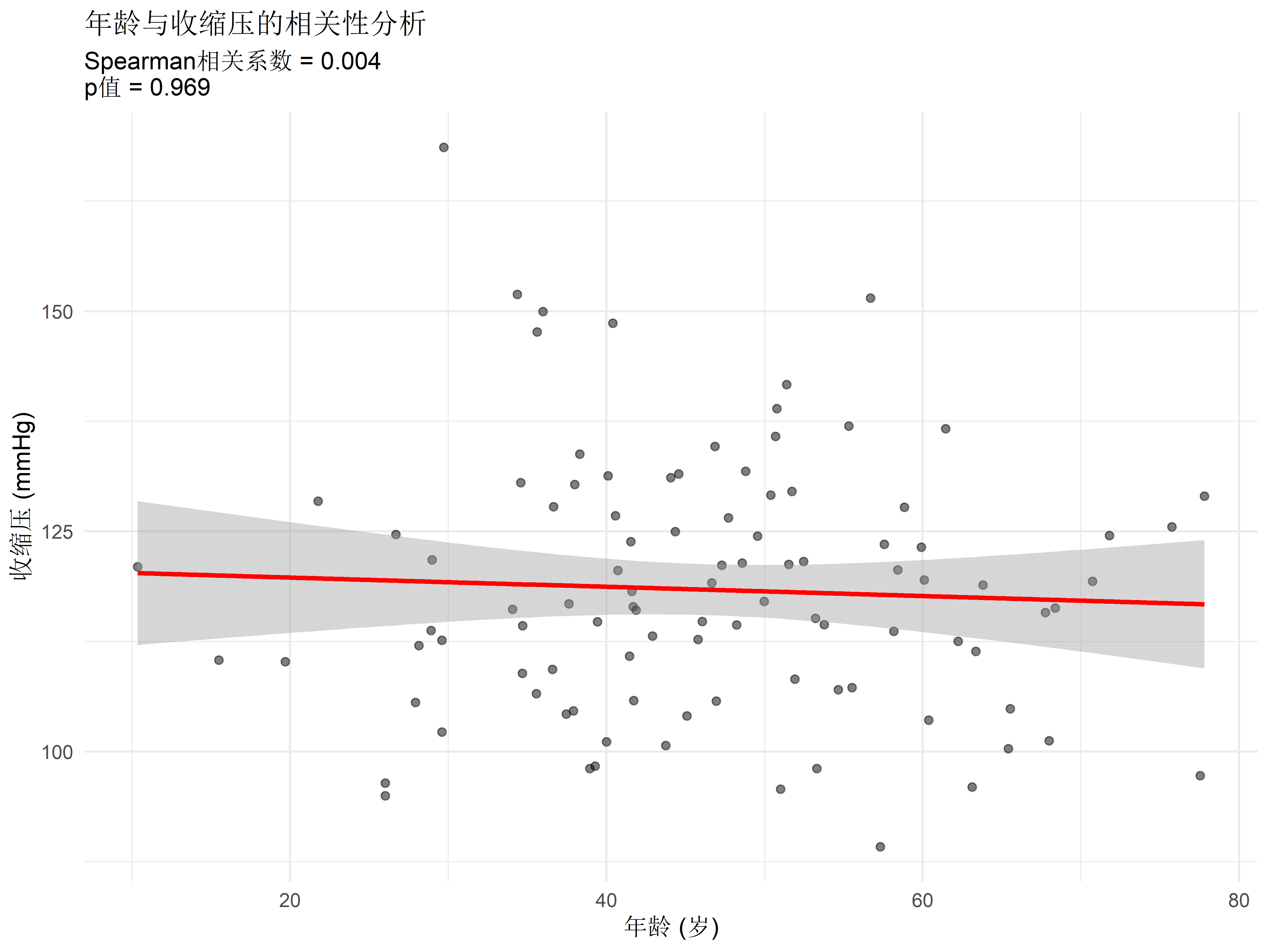
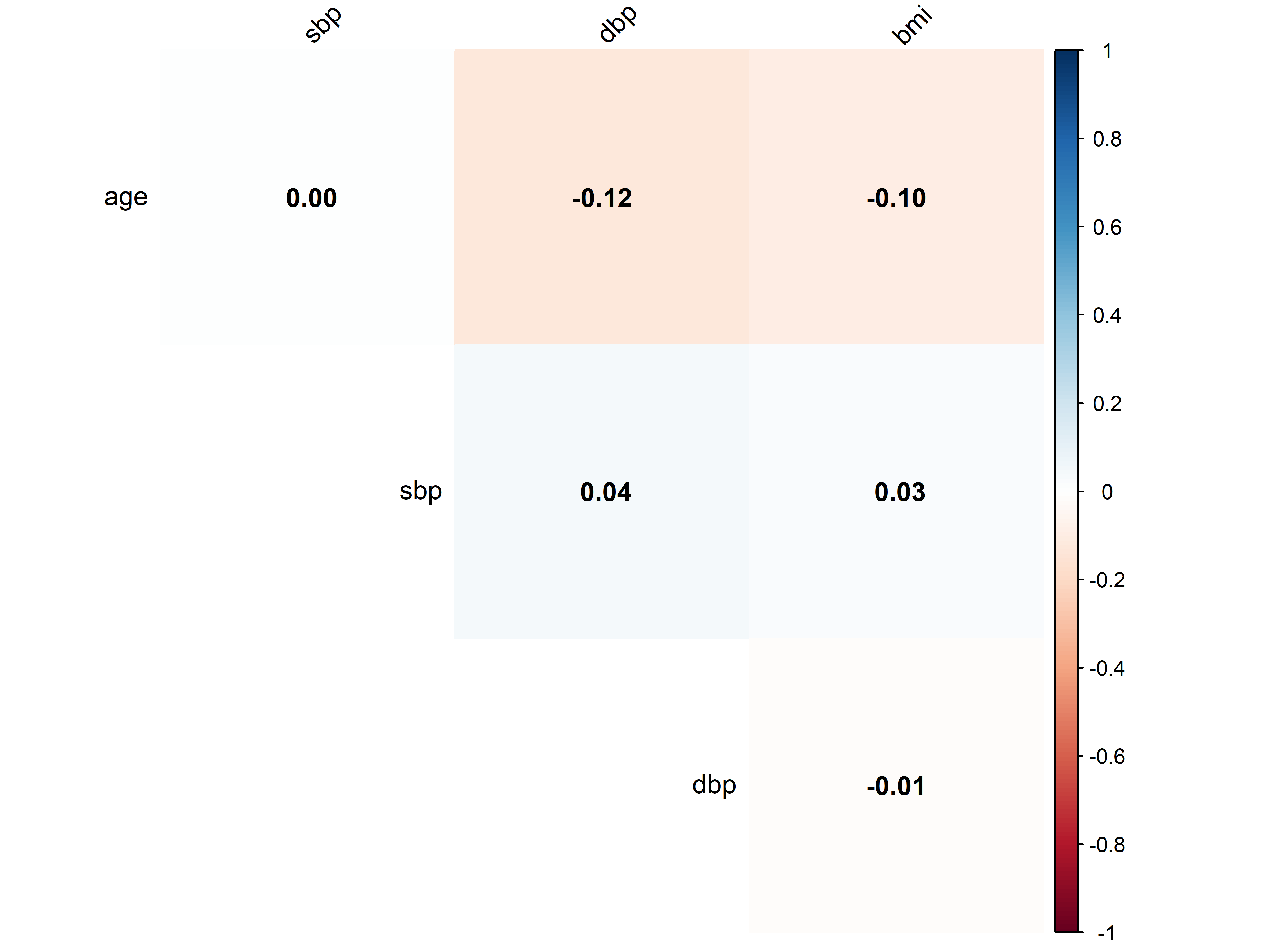
# 基础统计分析 {#sec-basic-stats} ```{r} #| label: check-packages #| message: false # 检查并安装所需的R包 <- c ("tidyverse" , # 数据处理和可视化 "gtsummary" , # 统计表格生成 "broom" , # 统计结果整理 "corrplot" , # 相关矩阵可视化 "medicaldata" , # 医学数据集 "vcd" # 可视化分类数据 # 检查并安装缺失的包 <- required_packages[! (required_packages %in% installed.packages ()[,"Package" ])]if (length (new_packages)) install.packages (new_packages)# 加载所有包 invisible (lapply (required_packages, library, character.only = TRUE ))``` ## 描述性统计 {#sec-descriptive} ### 连续变量(年龄、BMI) {#sec-continuous} ```{r} #| label: setup #| message: false # 创建示例数据 set.seed (123 )<- data.frame (age = rnorm (100 , mean = 45 , sd = 15 ),temp = rnorm (100 , mean = 37 , sd = 0.5 ),gender = factor (sample (c ("男" , "女" ), 100 , replace = TRUE )),group = factor (sample (c ("对照组" , "治疗组" ), 100 , replace = TRUE ))# 基本描述性统计 <- patient_data %>% select (age, temp) %>% summary ()print (patient_summary)# 使用gtsummary创建更专业的统计表 %>% select (age, temp, gender, group) %>% tbl_summary (by = group,statistic = list (all_continuous () ~ "{mean} ({sd})" ,all_categorical () ~ "{n} ({p}%)" digits = all_continuous () ~ 1 %>% add_p () %>% add_n () %>% modify_header (label = "**变量**" )``` ### 分类变量(性别、疾病分期) {#sec-categorical} ```{r} #| label: categorical-analysis # 创建分类数据 <- data.frame (gender = factor (rep (c ("男" , "女" ), each = 100 )),treatment = factor (sample (c ("治疗A" , "治疗B" , "治疗C" ), 200 , replace = TRUE )),response = factor (sample (c ("有效" , "无效" ), 200 , replace = TRUE , prob = c (0.7 , 0.3 )))# 创建列联表 <- table (cat_data$ treatment, cat_data$ response)print ("治疗方案与疗效的分布:" )print (treatment_response)# 使用gtsummary创建分类变量摘要 %>% tbl_summary (by = treatment,missing = "no" %>% add_p () %>% modify_spanning_header (c ("stat_1" , "stat_2" , "stat_3" ) ~ "治疗方案" )``` ## 统计推断方法 {#sec-inference} ### t检验(药物组间比较) {#sec-t-test} ```{r} #| label: t-test # 创建两组治疗数据 set.seed (123 )<- data.frame (group = factor (rep (c ("对照组" , "治疗组" ), each = 50 )),value = c (rnorm (50 , mean = 100 , sd = 15 ), # 对照组 rnorm (50 , mean = 110 , sd = 15 ) # 治疗组 # 进行t检验 <- t.test (value ~ group, data = treatment_data)# 创建可视化比较 ggplot (treatment_data, aes (x = group, y = value, fill = group)) + geom_boxplot () + labs (title = "治疗效果比较" ,subtitle = paste ("p值 =" , format.pval (t_test_result$ p.value, digits = 3 )),x = "分组" ,y = "测量值" ) + theme_minimal ()``` ### 卡方检验(发病率差异) {#sec-chi-square} ```{r} #| label: chi-square # 创建分类数据 <- data.frame (gender = factor (rep (c ("男" , "女" ), each = 100 )),disease = factor (c (sample (c ("是" , "否" ), 100 , replace = TRUE , prob = c (0.3 , 0.7 )),sample (c ("是" , "否" ), 100 , replace = TRUE , prob = c (0.2 , 0.8 ))# 进行卡方检验 <- chisq.test (table (disease_data$ gender, disease_data$ disease))# 创建马赛克图 library (vcd)mosaic (~ gender + disease, data = disease_data,main = "性别与疾病发生率关系" ,shade = TRUE )# 打印结果 print (chi_result)# 创建列联表可视化 <- table (disease_data$ gender, disease_data$ disease)print ("性别与疾病的分布:" )print (disease_table)``` ## 相关性分析 {#sec-correlation} ### Pearson/Spearman相关 {#sec-correlation-analysis} ```{r} #| label: correlation # 创建示例数据进行相关性分析 set.seed (123 )<- data.frame (age = rnorm (100 , mean = 45 , sd = 15 ),sbp = rnorm (100 , mean = 120 , sd = 15 ),dbp = rnorm (100 , mean = 80 , sd = 10 ),bmi = rnorm (100 , mean = 24 , sd = 3 )# 计算相关系数 <- cor.test (cor_data$ age, cor_data$ sbp,method = "spearman" )# 创建散点图 ggplot (cor_data, aes (x = age, y = sbp)) + geom_point (alpha = 0.5 ) + geom_smooth (method = "lm" , color = "red" ) + labs (title = "年龄与收缩压的相关性分析" ,subtitle = paste ("Spearman相关系数 =" , round (cor_test$ estimate, 3 )," \n p值 =" , format.pval (cor_test$ p.value, digits = 3 )),x = "年龄 (岁)" ,y = "收缩压 (mmHg)" ) + theme_minimal ()``` ### 相关系数矩阵可视化 {#sec-correlation-matrix} ```{r} #| label: correlation-matrix library (corrplot)# 计算相关系数矩阵 <- cor (cor_data, method = "spearman" )# 创建相关系数矩阵图 corrplot (cor_matrix,method = "color" ,type = "upper" ,addCoef.col = "black" ,tl.col = "black" ,tl.srt = 45 ,diag = FALSE )``` ## 练习 1. 使用自己的数据集进行描述性统计分析2. 比较两组患者的实验室指标差异3. 分析疾病发生率在不同人群中的差异4. 探索多个临床指标之间的相关性## 本章小结 1. 如何进行基本的描述性统计分析2. t检验和卡方检验的应用3. 相关性分析方法4. 使用专业的统计表格和图形展示结果