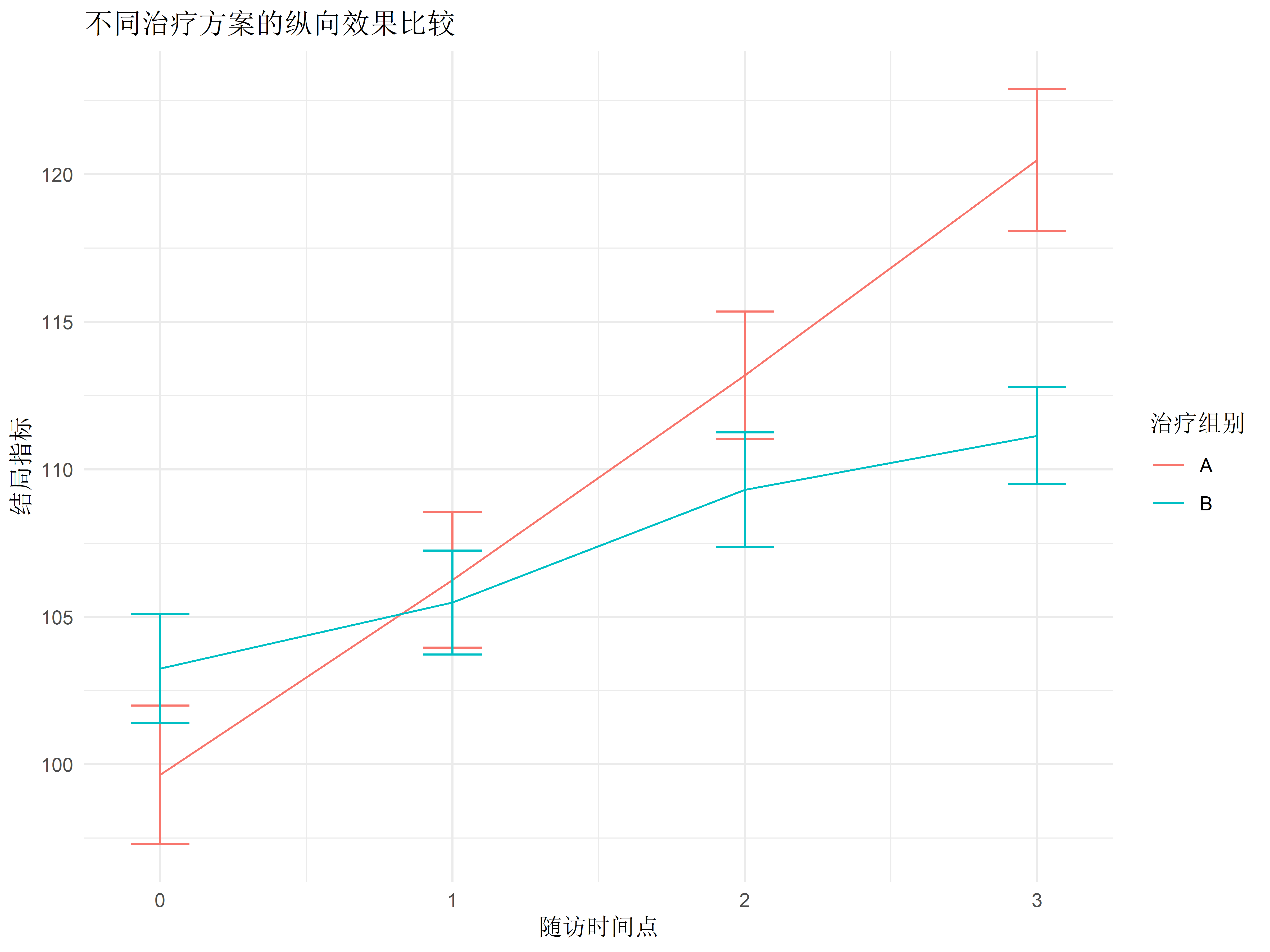
library(lme4)library(nlme)# 创建示例纵向数据set.seed(123)n_subjects <-50n_timepoints <-4longitudinal_data <-data.frame(subject =rep(1:n_subjects, each = n_timepoints),time =rep(0:3, times = n_subjects),treatment =rep(rep(c("A", "B"), each = n_subjects/2), each = n_timepoints))# 添加结局变量longitudinal_data$outcome <-with(longitudinal_data, { baseline <-rnorm(n_subjects, mean =100, sd =10)[subject] time_effect <-5* time treatment_effect <-ifelse(treatment =="A", 2, -2) * time random_effect <-rnorm(n_subjects, mean =0, sd =5)[subject] error <-rnorm(n_subjects * n_timepoints, mean =0, sd =3) baseline + time_effect + treatment_effect + random_effect + error})# 拟合混合效应模型mixed_model <-lmer(outcome ~ time * treatment + (1|subject), data = longitudinal_data)# 模型摘要summary(mixed_model)
Linear mixed model fit by REML ['lmerMod']
Formula: outcome ~ time * treatment + (1 | subject)
Data: longitudinal_data
REML criterion at convergence: 1186.7
Scaled residuals:
Min 1Q Median 3Q Max
-2.13216 -0.53827 -0.06963 0.57655 2.94331
Random effects:
Groups Name Variance Std.Dev.
subject (Intercept) 97.750 9.887
Residual 8.929 2.988
Number of obs: 200, groups: subject, 50
Fixed effects:
Estimate Std. Error t value
(Intercept) 99.4758 2.0396 48.772
time 6.9463 0.2673 25.990
treatmentB 3.6965 2.8844 1.282
time:treatmentB -4.1974 0.3780 -11.105
Correlation of Fixed Effects:
(Intr) time trtmnB
time -0.197
treatmentB -0.707 0.139
tim:trtmntB 0.139 -0.707 -0.197